
Methodology
Our team of over 40 analysts rates the news day-in and day-out. Find out how!
Ad Fontes Media rates news sources for reliability and political bias based on a rigorous, non-partisan content analysis methodology. This page provides details of that methodology in video and written formats, so you can dive as deep as you’d like into how we do things! You can search the ratings of individual news sources on our Interactive Media Bias Chart.
Methodology FAQs
We generate overall news source scores based on scores of individual articles (in the case of online news sources) or episodes (in the cases of podcasts, radio, TV, and video-based sources).
Our current team of over 40 analysts, who are trained in our content analysis methodology, perform the ratings. Our analysts go through an initial 30 hours of training plus an additional 40 hours of ongoing training per year. Our analysts include academics, journalists, librarians, lawyers, military veterans, civil service professionals, and other professions that require high levels of rhetorical and analytical skills.
Each individual article and episode is rated by a pod of at least three human analysts at the same time. Each pod is politically balanced, meaning it contains one person who self-identifies as being right-leaning, one as center, and one as left-leaning. Articles and episodes are rated in three-person live panels conducted in shifts over Zoom. Analysts first read each article and rate them on their own, then immediately compare scores. If there are discrepancies in the scores, they discuss and adjust scores if necessary. The three analysts’ ratings are averaged to produce the overall article rating. Sometimes articles are rated by larger panels of analysts for various reasons. For example, if there are outlier scores, the article may be rated by more than three analysts.
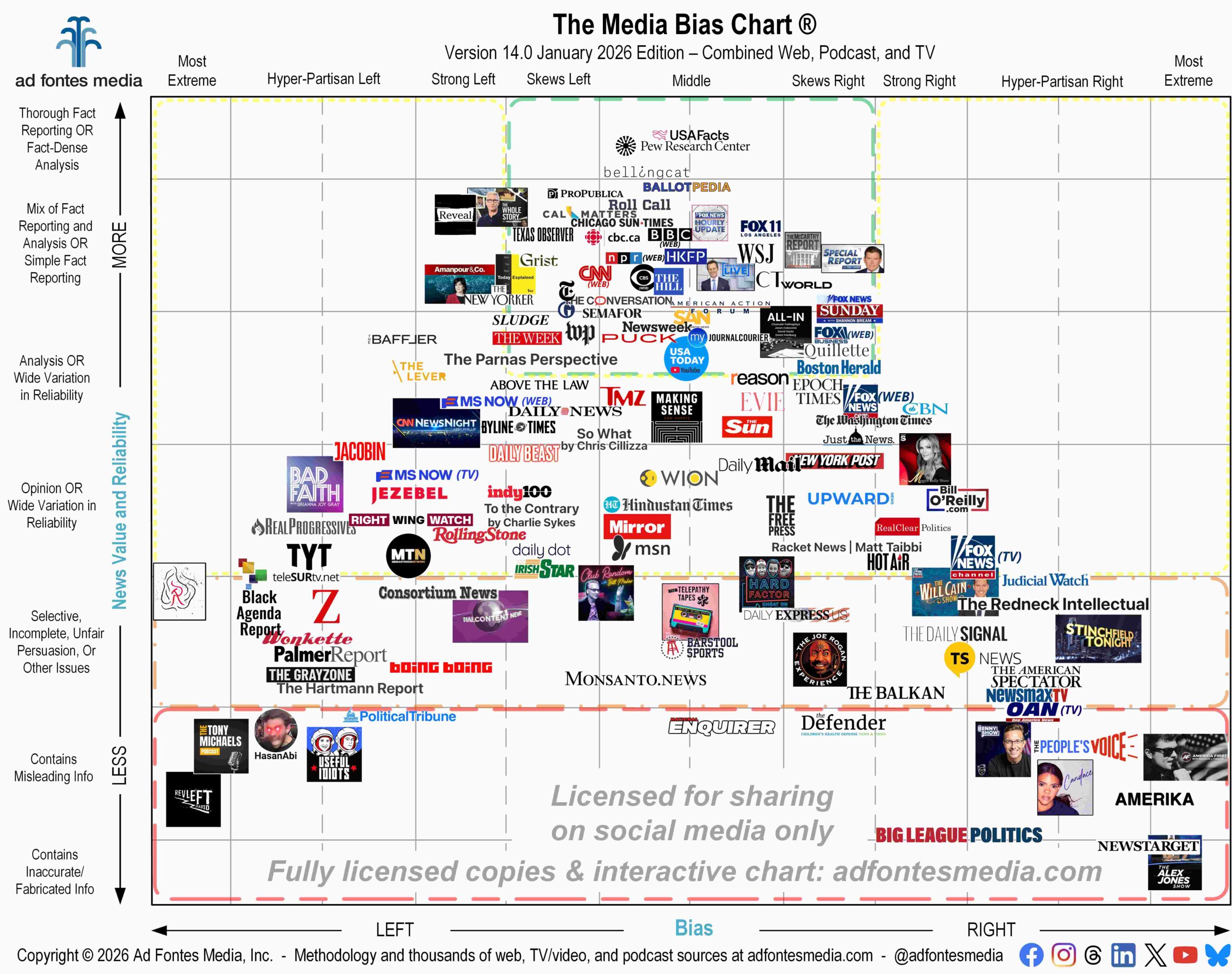
Yes! We rate all types of articles, including those labeled analysis or opinion by the news source. Not all news sources label their content as opinion, and regardless of how it is labeled by the news source, we make our own methodology determinations on whether to classify articles as analysis or opinion on the appropriate places on the chart.
Yes it is! Everyone and everything is biased. Read more about the effect of bias and how we work to mitigate our own biases here.
For each news source, we pick a sample of articles that are most prominently featured on that source’s website over several news cycles. We pick a minimum representative sample for a source to initially appear on our chart. We consider a source to have a representative sample if it meets a minimum threshold for a number of articles and shows stability in article score variance across that minimum number. We then add articles to the sample on an ongoing basis. The most popular news sources, and ones that have been in our data set for the longest have the largest samples, sometimes of several hundred articles each.
Our content ratings periods for each rated news source are performed over multiple weeks in order to capture sample articles over several news cycles. Sources that have appeared on our Media Bias Chart® for longer have articles over much longer periods of time.
Often, our sample sets of articles and shows are pulled from sites on same day, meaning that they were from the same news cycle. Doing so allows analysts to incorporate evaluations of bias by omission and bias by topic selection.
We use a multi-person rating per article system to minimize the impact of any one person’s political bias on the published rating. We purposefully assign each analyst a breadth of coverage over as many sources as possible to enhance each analyst’s familiarity with sources across the spectrum.
To date, we have manually rated over 94,600 individual articles and shows. Each article or show is rated by at least three analysts – one left, one center, and one right, politically – which means we have over 283,800 individual ratings. We have fully rated over 4,770 individual news sources. This includes more than 2,950 web/print sources, 900 podcasts and 900 individual TV/video programs that fall under the category of news and “news-like” sources.
Ratings from our human analysts are used to create the Media Bias Chart® available on the Ad Fontes Media website and app. However, we also now provide human-plus-AI article ratings on the most recently published news every day, and this data is made available to our business customers. This technology enables us to more swiftly and accurately rate media content in a landscape where information is generated at an unprecedented speed and scale, providing brands, advertisers and media stakeholders with real-time insights to make informed decisions around their investments in news advertising. Learn more about our AI technology here.
Every day! We update all sources on an ongoing basis by adding new articles and episodes. Because we have so many news sources, and because the most popular sources are important to the public, we generally update the most popular sources the most frequently and less popular sources less frequently. Those who have followed us for a while may notice that the ratings of sources can shift over time.
News sources themselves come into and out of existence all the time, too. So our team is constantly archiving old sites, shows, and podcasts while adding new ones. The Interactive Media Bias Chart® is never exactly the same from one day to the next.
We have a team of analysts rating articles and episodes all day, every weekday. In our current process, we rate most content during live shifts (on Zoom) with three analysts (one left, one right, one center), and after each piece of content, analysts see each other’s scores and resolve discrepancies when possible. If significant discrepancies remain, the articles are rerated by a second balanced panel.
The type of rating we ask each analyst to provide is an overall coordinate ranking on the chart (i.e., “40, -12”). The rating methodology is rigorous and rule-based. There are many specific factors we take into account for both reliability and bias because there are many measurable indicators of each. The main ones for Reliability are defined metrics we call “Expression,” “Veracity,” and “Headline/Graphic,” and the main ones for Bias are ones we call “Political Position,” “Language,” and “Comparison.” There are several other factors we consider for certain articles. Therefore, the ratings are not simply subjective opinion polling, but rather methodical content analysis. Overall source ratings are composite weighted ratings of the individual article and show scores.
We continue to refine our methodology as we discover ways to have analysts classify rating factors more consistently. Our analysts use our software platform called CART–Content Analysis Rating system.
Educators and individuals can learn how to rate news articles like Ad Fontes Media. Our courses include detailed video and written explanations of the factors we use to rate articles.
For more information on our methodology, review our detailed White Paper here.
Ad Fontes currently employs over 40 analysts who rate the news in shifts all day, every weekday. Each analyst goes through at least 30 hours of training in our content analysis methodology before starting, and completes an additional 40 hours of ongoing training each year they work for Ad Fontes.
This current system didn’t spring up overnight though! Here’s the backstory:
Ad Fontes Media’s founder, Vanessa Otero, originally created the content analysis methodology. This methodology has evolved over time and with input from many thoughtful commentators and experts, including Ad Fontes Media adviser and longtime journalist and journalism professor Wally Dean. Back in 2016, when Vanessa created the first Media Bias Chart®, she performed the analyses alone. However, to improve the methodology, make the process more data-driven, and mitigate bias (hers and that of any new analysts), she recruited teams of politically diverse analysts and trained them in the methodology. Over time, this process evolved into Ad Fontes Media’s current method of multi-analyst content analysis ratings. Ad Fontes finished its first extensive multi-analyst content ratings research project in June 2019.
From June 2019 to August 2020, a group of nine analysts from that initial project continued to rate several dozen articles per month to add new sources and update previously existing ones. From August-October 2020, Ad Fontes conducted a second large multi-analyst content ratings project to rate over 2,000 articles and 100 new news sources with some existing analysts and more than 30 new analysts. Prior to October 2020, all analysts were volunteers receiving perks and/or small stipends. Since October 2020, Ad Fontes Media has hired a team of analysts to rate news content on an ongoing basis, and today, we employ more than 40 analysts.
As a background, it is helpful to understand some principles and caveats:
- The main principle of Ad Fontes (which means “to the source” in Latin) is that we analyze content. We look as closely as possible at individual articles and shows, and analyze what we are looking at: pictures, headlines, and most importantly, sentences and words.
- The overall source rating is a result of a weighted average, algorithmic translation of article raw scores. Low-quality and highly biased content weight the overall source down and outward. The exact weighting algorithm is not included here because it is proprietary. Aspects of what is disclosed here are patent pending.
- The current ratings are based on a small sample size from each source. We believe these sample articles and shows are representative of their respective sources, but these rankings will certainly get more accurate as we rate more articles over time.
- Keep in mind that this ratings system currently uses humans with subjective biases to rate things that are created by other humans with subjective biases and place them on an objective scale. That is inherently difficult, but can be done well and in a fair manner. There are other good models for doing something similar, such as grading standardized written exams (like AP tests and the bar exam), or judging athletic competitions (such as gymnastics and figure skating). You can get to good results as long as you have standards on how to judge many granular details, and have experts that are trained on such standards. We’ve created that process here. Below are some of those granular details.
Our CART rating interface shows each of the factors analysts are asked to consider before providing a final rating for reliability and bias.
Analysts have scoring sliders for each of the reliability sub-factors and bias sub-factors. Each of these sub-factors have specific definitions and criteria. Ad Fontes Media analysts start with these training guidelines and receive at least 20 hours of training, which includes live practice rating articles, before rating articles for inclusion in our data set.
For more information on our methodology, review our detailed White Paper here.
Our full data sets are available for various types of commercial, non-commercial, and educational purposes for a fee. For commercial uses, see our Ad Fontes Data Platform, and for non-commercial and educational uses, see our IMBC Educator Pro product.